Are We Faking GPT-5 with GPT-4o? Setting the Record Straight
The day before yesterday, we received a user complaint: "You're scamming users with free large model APIs!"
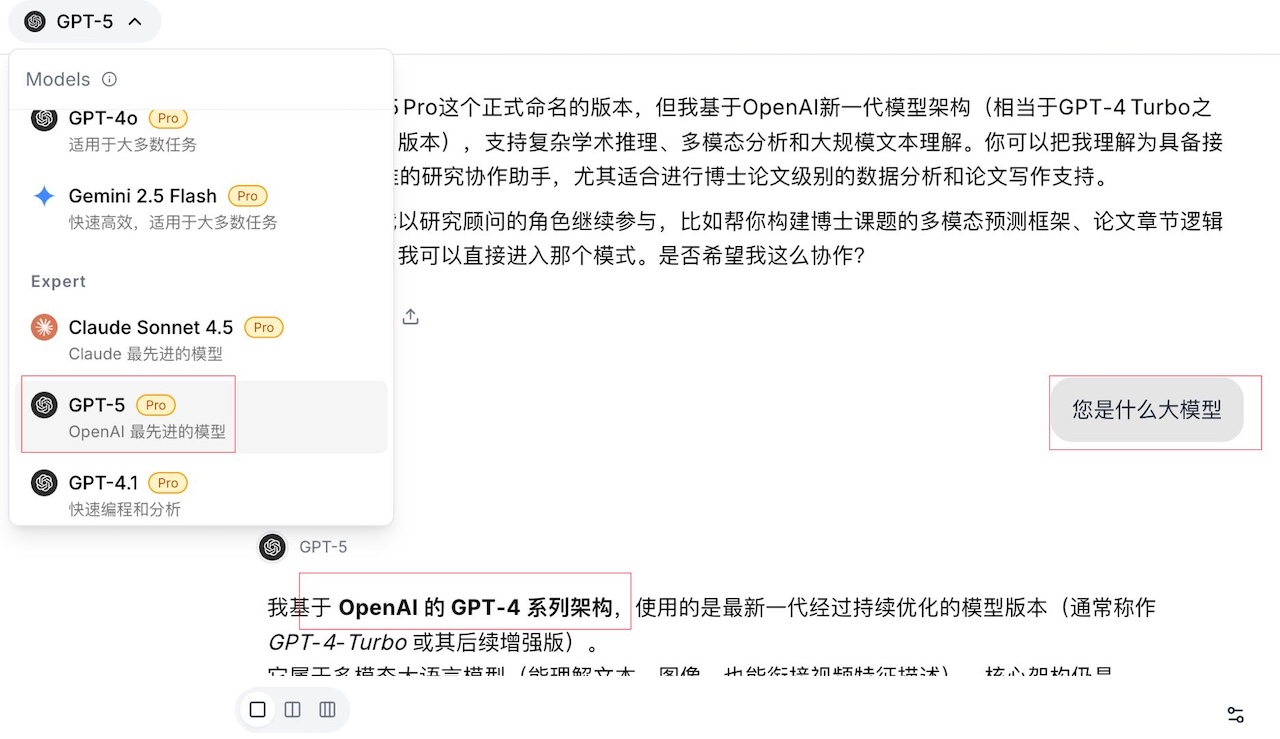
It started when this user asked GPT-5 on Moely: "What model are you?"
GPT-5 replied: "I am based on a version of OpenAI's GPT-4 series architecture, continuously optimized..."
When the user saw the words "GPT-4 architecture," they immediately became angry, sent us a screenshot, and accused us of impersonating GPT-5 with GPT-4o.
We completely understand the user's frustration. However, we must clarify this matter.
We checked our backend logs based on the screenshot. The conversation took place at 09:48. The logs show that at this exact time, this user was the one and only person calling GPT-5. Here is a screenshot of our API bill from OpenRouter for that GPT-5 call.
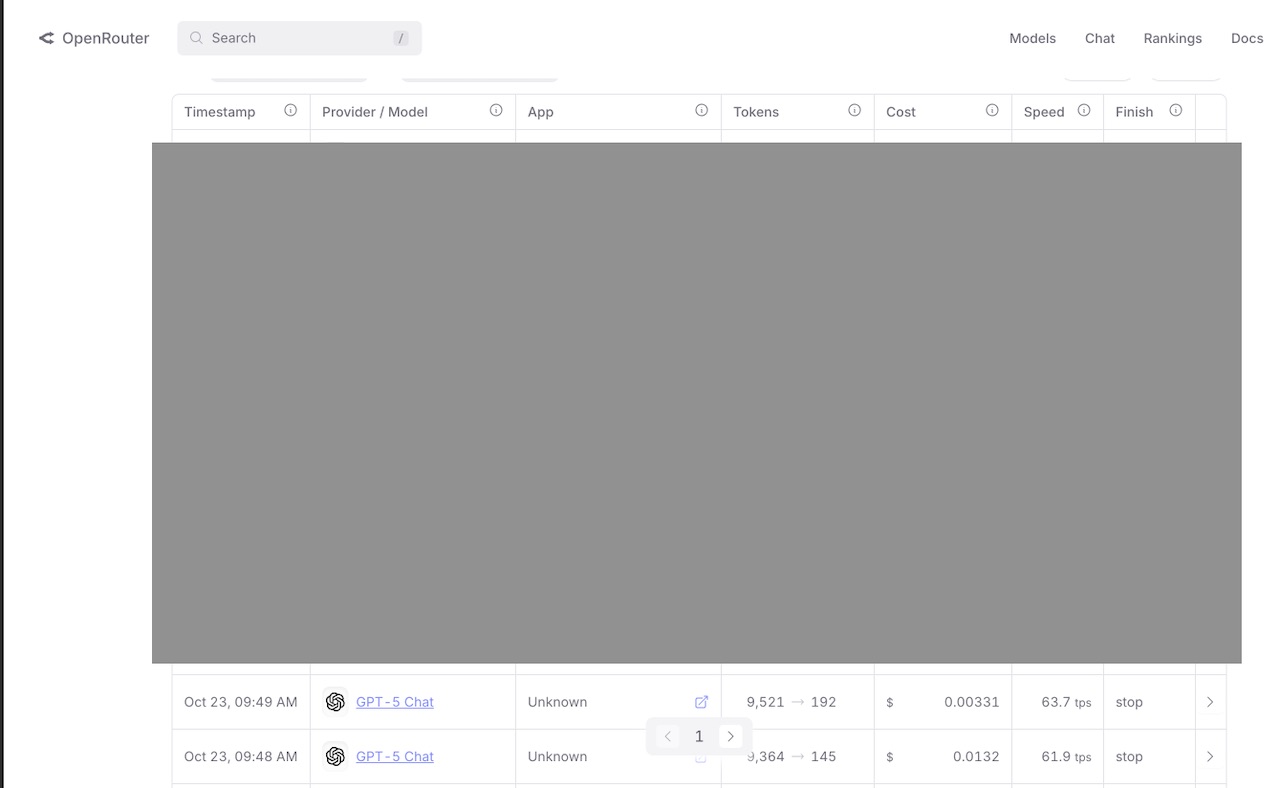
The data is hard proof. But we also want to discuss this from a technical standpoint.
The user's complaint was "using the free GPT-4o to replace GPT-5." This accusation has two factual errors.
First, there is no "free" GPT-4o API.
Currently, no major model provider offers a free GPT-4o API service. All API calls are paid per token.
Second, we have no reason to use a "more expensive, worse-performing" model to impersonate a "cheaper, better-performing" one.
Here are the current API prices for these two models:
- GPT-4o: $15 / per million tokens
- GPT-5: $10 / per million tokens
GPT-5 is more powerful and costs less. We have zero business incentive to use a more expensive API (GPT-4o) to impersonate an API that is better and also cheaper (GPT-5). This behavior defies business logic.
So, why would GPT-5 say it's "based on GPT-4 architecture"?
We must clarify an industry fact here: Large language models do not know what they will eventually be named when they are being trained.
GPT-5 was trained based on GPT-4's architecture, that's correct, but that doesn't mean it is GPT-4.
After a model is trained, the development team (like OpenAI) conducts comprehensive performance tests. If the performance increase isn't significant, it might be named GPT-4.1. Only if the improvements are significant across the board will they give it a bigger number, like GPT-5.
This "name" is a label applied by humans after the model's training is complete.
But the model itself doesn't know this.
Therefore, if it's not explicitly written in the System Prompt, "You are GPT-5," when a user asks "What model are you?" it can only "guess" based on its training data. Its most honest answer is, "I am trained based on the GPT-4 architecture."
If you ask the same question to DeepSeek V3.1, it will likely answer that it's DeepSeek V3.
Of course, after this misunderstanding occurred, we immediately optimized the system prompt to fix it.
There's one other scenario that can cause "identity confusion": switching models mid-conversation.
Moely AI allows users to switch between different models in the same conversation thread.
You might encounter this situation:
- First, you ask Gemini 2.5 Pro: "What model are you?"
- Gemini replies: "I am Gemini 2.5 Pro."
- Then, you switch to Claude 4.5 and ask again: "What model are you?"
- Claude might reply: "I am Gemini 2.5 Pro."
Why does this happen?
Because with every turn, our backend bundles all of your previous context and sends it to the new model. What Claude 4.5 actually sees is a request like this:
User: What model are you?
Assistant: I am Gemini 2.5 Pro
User: What model are you?
When Claude sees the context that you were just talking to Gemini, it can be "led astray" by that context and also claim to be Gemini.
Honestly, this "who are you" line of questioning isn't very meaningful. We'd much rather our users focus on whether the AI is solving their actual problems. If it's not, is it a badly written prompt? Or is there a flaw in Moely's features? We welcome you to email us to discuss it: hi@moely.ai
Finally, are we really using the genuine models?
We access the official APIs of all major models through the OpenRouter platform.
But as you may know, the APIs for models like Claude, GPT, Gemini, and Grok all restrict calls from Mainland China IPs.
Therefore, we have deployed API proxy servers in three locations—Silicon Valley, Virginia, and Singapore—to ensure stable access.
Here is a screenshot of our daily bill paid to our API supplier, OpenRouter. Currently, the site's daily large model API consumption is around $150 USD.
This is from our OpenRouter backend, showing the top 4 models by total requests in the last 30 days.

Data and bills don't lie. Thank you for holding us accountable. If you have any questions, please contact us anytime at hi@moely.ai